Construindo uma API em Go para gerenciar arquivos no Amazon S3

Quando decidi criar meu blog, escolhi o Amazon S3 para hospedar as imagens dos posts. A decisão foi prática (S3 é confiável, barato e escala bem), mas eu também vi ali uma oportunidade: usar um problema real do dia a dia para aprofundar minha fluência no ecossistema AWS, especialmente em segurança, automação e integrações.
Depois de ter criado um programa em Go que me permite otimizar e converter para WebP, o qual detalhei nesse artigo, resolvi criar uma API também em Go, que me permite gerenciar minha conta na AWS, com isso posso fazer upload individual ou múltiplo de arquivos, gerenciamento de buckets, listagem inteligente e downloads eficientes via streaming.
Foi aí que surgiu esta API: uma aplicação em Go que me permite gerenciar arquivos e buckets no S3 com um fluxo pensado para produtividade, upload único ou múltiplo, listagem paginada, download via streaming e geração de URL temporária (presigned URL) para acesso seguro.
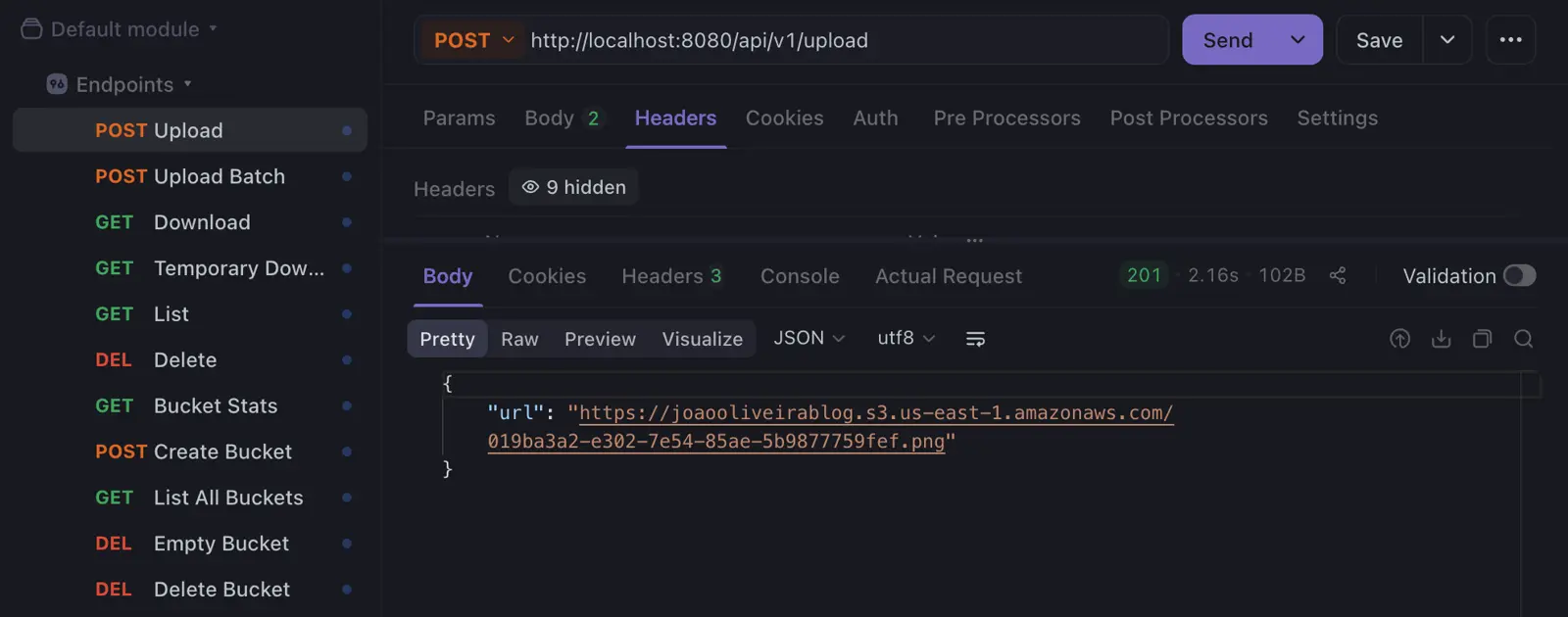
Para garantir agilidade no dia a dia, a aplicação é totalmente containerizada com Docker. Assim, eu subo o container e uso os endpoints (que já deixo salvos no Apidog). A cada upload, recebo instantaneamente o link final do arquivo, pronto para colar no post. Esse é o fluxo “fácil e rápido” que eu queria.
O que essa API faz
De forma resumida, esta API cobre:
- Uploads individuais e múltiplos (com concorrência).
- Listagem paginada de objetos com metadados úteis.
- Download via streaming, evitando carregar arquivos inteiros na memória da API.
- Presigned URLs para acesso temporário e seguro a buckets privados.
- Gerenciamento de buckets (criar, listar, estatísticas, esvaziar e remover).
Arquitetura e Estrutura do Projeto
Estruturei o projeto seguindo as recomendações do Go Standards Project Layout. Essa organização, inspirada em Clean Architecture, permite que a aplicação nasça robusta, facilitando a evolução de funcionalidades e a manutenção a longo prazo.
Como cada parte se conecta
Uma forma simples de entender a arquitetura é imaginar um fluxo:
- Handler (HTTP): traduz protocolo, valida o mínimo e devolve resposta.
- Service: aplica regras, validações, segurança, concorrência e timeouts.
- Repository (interface): contrato de armazenamento.
- S3 Repository (implementação): detalhes de integração com AWS SDK.
Estrutura de diretórios
s3-api/
├── .github/
│ └── workflows/ # CI: pipelines (testes, lint, build) no GitHub Actions
├── cmd/
│ └── api/
│ └── main.go # Bootstrap: carrega config, inicializa dependências e sobe o HTTP server
├── internal/
│ ├── config/ # Configuração centralizada: env vars tipadas + defaults
│ ├── middleware/ # Middlewares HTTP: logging, timeout, recovery, etc.
│ └── upload/ # Módulo de domínio (arquivos e buckets no S3)
│ ├── entity.go # Entidades e DTOs de resposta (modelos do domínio)
│ ├── errors.go # Erros de domínio (sem acoplamento a HTTP)
│ ├── repository.go # Contrato (interface) de storage
│ ├── s3_repository.go # Implementação do contrato usando AWS SDK v2
│ ├── service.go # Regras de negócio: validações, concorrência, timeouts
│ ├── handler.go # HTTP handlers: traduz request/response e chama o Service
│ └── service_test.go # Testes unitários do Service (com mocks do Repository)
├── .env # Config local (NUNCA versionar; usar .gitignore)
├── Dockerfile # Build multi-stage (binário enxuto)
└── docker-compose.yml # Ambiente local: sobe API com env/portsDecisões importantes nessa estrutura
cmd/api/main.go: Aqui aplicamos a Injeção de Dependência. O main cria o cliente da AWS, o repositório e o serviço, conectando-os. Se amanhã quisermos mudar o S3 para um banco local, mudamos apenas uma linha aqui.internal/middleware/: Implementamos um middleware de Logging estruturado (usandoslog) e um de Timeout, garantindo que nenhuma requisição fique pendurada infinitamente, protegendo a saúde da aplicação.internal/upload/service.go: É aqui que usamos concorrência avançada comerrgroup. Ao fazer uploads múltiplos, o serviço dispara várias goroutines para falar com o S3 em paralelo, reduzindo drasticamente o tempo de resposta.internal/upload/errors.go: Em vez de retornar strings genéricas, usamos erros tipados. Isso permite que o Handler identifique se deve retornar um400 Bad Requestou um404 Not Foundde forma elegante.
Endpoints
A API foi dividida em dois grandes grupos: gerenciamento de Arquivos e de Buckets.
Files
| Method | Endpoint | Description |
|---|---|---|
| POST | /api/v1/upload | Upload de 1 arquivo |
| POST | /api/v1/upload-multiple | Upload múltiplo |
| GET | /api/v1/list | Listagem paginada |
| GET | /api/v1/download | Download via streaming |
| GET | /api/v1/presign | Gera URL temporária (presigned) |
| DELETE | /api/v1/delete | Remove o objeto do bucket |
Buckets
| Method | Endpoint | Description |
|---|---|---|
| GET | /api/v1/buckets/list | Lista buckets da conta |
| POST | /api/v1/buckets/create | Cria bucket |
| GET | /api/v1/buckets/stats | Estatísticas |
| DELETE | /api/v1/buckets/delete | Remove o bucket |
| DELETE | /api/v1/buckets/empty | Esvazia bucket |
Pontos de destaque e decisões técnicas
Decisões que mais impactam o uso real da API
UUID v7 para nomes de arquivos
Nos uploads eu uso UUID v7 para renomear os arquivos. Além de evitar colisões e exposição de nomes originais, o v7 preserva ordenação temporal. Isso ajuda na organização no S3, facilita auditoria e deixa o caminho aberto para evolução futura (por exemplo, indexação em banco sem perder ordenação).
Streaming para evitar picos de memória
No download, a ideia é manter o consumo de RAM estável. Em vez de “baixar tudo e depois devolver”, eu trato como um fluxo: os dados saem do S3 e vão para o cliente sem precisar virar um buffer gigante dentro da API.
Validação real de tipo de arquivo (MIME)
Extensão é fácil de falsificar. Por isso, em vez de confiar no .jpg/.png, eu valido o conteúdo do arquivo (header) para identificar o tipo real. Isso reduz a chance de subir conteúdo malicioso disfarçado como imagem.
Timeouts como proteção de recursos
Como a API depende de serviços externos (S3), eu não quero requisições “penduradas”. Timeouts impedem consumo excessivo de goroutines e conexões quando a rede está ruim ou quando há lentidão do provedor.
Inicializando o projeto
O primeiro passo é preparar o ambiente de desenvolvimento. O Go utiliza o sistema de módulos (go mod) para gerenciar dependências, o que garante que o projeto seja reprodutível em qualquer máquina.
# Criação da pasta raiz e entrada no diretório
mkdir s3-api && cd s3-api
# Inicialização do módulo (substitua pelo seu repositório se necessário)
go mod init github.com/JoaoOliveira889/s3-api
# Criação da árvore de diretórios seguindo o Go Standard Layout
mkdir -p cmd/api internal/upload internal/config internal/middlewareGerenciamento de Dependências
Eu uso o AWS SDK for Go v2 e algumas bibliotecas para dar robustez ao projeto (roteamento HTTP, carregamento de env, UUID, testes). A ideia é manter um conjunto enxuto e bem justificado, evitando dependências desnecessárias.
# Core do SDK e gerenciamento de configurações/credenciais
go get github.com/aws/aws-sdk-go-v2
go get github.com/aws/aws-sdk-go-v2/config
# Serviço específico do S3
go get github.com/aws/aws-sdk-go-v2/service/s3
# Gin Gonic: Framework HTTP de alta performance
go get github.com/gin-gonic/gin
# GoDotEnv: Para carregar variáveis de ambiente do arquivo .env
go get github.com/joho/godotenv
# UUID: Para geração de identificadores únicos v7
go get github.com/google/uuid
# Testify: Para facilitar a criação de asserções e mocks nos testes
go get github.com/stretchr/testifyCamada de Domínio
Aqui entram as entidades e os contratos. O ponto central é: o domínio descreve o que o sistema faz, sem acoplamento ao S3 em si.
Entidades
As entidades representam os dados principais da aplicação: arquivos, metadados para listagem, estatísticas de bucket e paginação.
package upload
import (
"io"
"time"
)
type File struct {
Name string `json:"name"`//nome final do objeto no storage
URL string `json:"url"`//URL resultante após upload
Content io.ReadSeekCloser `json:"-"`//Content não é serializado em JSON porque representa o stream do arquivo
Size int64 `json:"size"`
ContentType string `json:"content_type"`
}
type FileSummary struct {
Key string `json:"key"`//chave completa do objeto no S3
URL string `json:"url"`
Size int64 `json:"size_bytes"`
HumanReadableSize string `json:"size_formatted"`
Extension string `json:"extension"`
StorageClass string `json:"storage_class"`
LastModified time.Time `json:"last_modified"`
}
type BucketStats struct {
BucketName string `json:"bucket_name"`
TotalFiles int `json:"total_files"`
TotalSizeBytes int64 `json:"total_size_bytes"`
TotalSizeFormatted string `json:"total_size_formatted"`
}
type BucketSummary struct {
Name string `json:"name"`
CreationDate time.Time `json:"creation_date"`
}
type PaginatedFiles struct {
Files []FileSummary `json:"files"`
NextToken string `json:"next_token,omitempty"`//token de continuação (pagination token)
}Interface do Repositório
O repositório define um contrato de armazenamento. Assim, o Service não “sabe” que é S3. Ele só sabe que existe uma implementação capaz de armazenar, listar, baixar e deletar.
Nota: ao trabalhar com stream no upload/download, a API evita carregar arquivos inteiros em memória, mantendo o consumo de RAM muito mais previsível.
package upload
import (
"context"
"io"
"time"
)
// Repository define o contrato de storage.
type Repository interface {
// Upload armazena o arquivo no bucket e retorna a URL final do objeto.
Upload(ctx context.Context, bucket string, file *File) (string, error)
// GetPresignURL gera uma URL temporária para download seguro
GetPresignURL(ctx context.Context, bucket, key string, expiration time.Duration) (string, error)
// Download retorna um stream (io.ReadCloser) para permitir streaming sem carregar tudo em memória.
Download(ctx context.Context, bucket, key string) (io.ReadCloser, error)
// List retorna uma página de arquivos usando token de continuação.
List(ctx context.Context, bucket, prefix, token string, limit int32) (*PaginatedFiles, error)
// Delete remove um objeto específico do bucket.
Delete(ctx context.Context, bucket string, key string) error
// CheckBucketExists verifica se o bucket existe e está acessível.
CheckBucketExists(ctx context.Context, bucket string) (bool, error)
// CreateBucket cria um bucket (geralmente com validações prévias na camada de Service).
CreateBucket(ctx context.Context, bucket string) error
// ListBuckets lista todos os buckets disponíveis na conta.
ListBuckets(ctx context.Context) ([]BucketSummary, error)
// GetStats agrega estatísticas do bucket
GetStats(ctx context.Context, bucket string) (*BucketStats, error)
// DeleteAll remove todos os objetos do bucket
DeleteAll(ctx context.Context, bucket string) error
// DeleteBucket remove o bucket
DeleteBucket(ctx context.Context, bucket string) error
}Camada de Infraestrutura
Com o contrato definido, eu crio a implementação concreta para falar com a AWS. Aqui o objetivo é traduzir as necessidades do domínio para chamadas do AWS SDK v2.
package upload
import (
"context"
"fmt"
"io"
"path/filepath"
"strings"
"time"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/service/s3"
"github.com/aws/aws-sdk-go-v2/service/s3/types"
)
type S3Repository struct {
client *s3.Client
region string
}
func NewS3Repository(client *s3.Client, region string) Repository {
return &S3Repository{
client: client,
region: region,
}
}
func (r *S3Repository) Upload(ctx context.Context, bucket string, file *File) (string, error) {
input := &s3.PutObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(file.Name),
Body: file.Content, //stream: evita carregar o arquivo inteiro em memória
}
_, err := r.client.PutObject(ctx, input)
if err != nil {
return "", fmt.Errorf("failed to upload: %w", err)
}
// URL direta
return fmt.Sprintf("https://%s.s3.%s.amazonaws.com/%s", bucket, r.region, file.Name), nil
}
func (r *S3Repository) List(ctx context.Context, bucket, prefix, token string, limit int32) (*PaginatedFiles, error) {
input := &s3.ListObjectsV2Input{
Bucket: aws.String(bucket),
Prefix: aws.String(prefix),
ContinuationToken: aws.String(token),
MaxKeys: aws.Int32(limit),
}
// No SDK, token vazio deve ser nil para evitar request com token inválido.
if token == "" {
input.ContinuationToken = nil
}
output, err := r.client.ListObjectsV2(ctx, input)
if err != nil {
return nil, fmt.Errorf("failed to list objects: %w", err)
}
var files []FileSummary
for _, obj := range output.Contents {
key := aws.ToString(obj.Key)
size := aws.ToInt64(obj.Size)
files = append(files, FileSummary{
Key: key,
Size: size,
HumanReadableSize: formatBytes(size),
StorageClass: string(obj.StorageClass),
LastModified: aws.ToTime(obj.LastModified),
Extension: strings.ToLower(filepath.Ext(key)),
URL: fmt.Sprintf("https://%s.s3.%s.amazonaws.com/%s", bucket, r.region, key),
})
}
next := ""
if output.NextContinuationToken != nil {
next = *output.NextContinuationToken
}
return &PaginatedFiles{Files: files, NextToken: next}, nil
}
func (r *S3Repository) Delete(ctx context.Context, bucket, key string) error {
_, err := r.client.DeleteObject(ctx, &s3.DeleteObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(key),
})
return err
}
func (r *S3Repository) Download(ctx context.Context, bucket, key string) (io.ReadCloser, error) {
output, err := r.client.GetObject(ctx, &s3.GetObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(key),
})
if err != nil {
return nil, err
}
// Retorna o Body como stream para o Handler fazer io.Copy direto na resposta.
return output.Body, nil
}
func (r *S3Repository) GetPresignURL(ctx context.Context, bucket, key string, exp time.Duration) (string, error) {
// Presign client gera URLs temporárias sem precisar tornar o objeto público.
pc := s3.NewPresignClient(r.client)
req, err := pc.PresignGetObject(ctx, &s3.GetObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(key),
}, s3.WithPresignExpires(exp))
if err != nil {
return "", err
}
return req.URL, nil
}
func (r *S3Repository) CheckBucketExists(ctx context.Context, bucket string) (bool, error) {
_, err := r.client.HeadBucket(ctx, &s3.HeadBucketInput{Bucket: aws.String(bucket)})
if err != nil {
return false, nil
}
return true, nil
}
func (r *S3Repository) CreateBucket(ctx context.Context, bucket string) error {
_, err := r.client.CreateBucket(ctx, &s3.CreateBucketInput{Bucket: aws.String(bucket)})
return err
}
func (r *S3Repository) ListBuckets(ctx context.Context) ([]BucketSummary, error) {
out, err := r.client.ListBuckets(ctx, &s3.ListBucketsInput{})
if err != nil {
return nil, err
}
var res []BucketSummary
for _, b := range out.Buckets {
res = append(res, BucketSummary{Name: aws.ToString(b.Name), CreationDate: aws.ToTime(b.CreationDate)})
}
return res, nil
}
func (r *S3Repository) DeleteBucket(ctx context.Context, bucket string) error {
_, err := r.client.DeleteBucket(ctx, &s3.DeleteBucketInput{Bucket: aws.String(bucket)})
return err
}
func (r *S3Repository) DeleteAll(ctx context.Context, bucket string) error {
out, err := r.client.ListObjectsV2(ctx, &s3.ListObjectsV2Input{Bucket: aws.String(bucket)})
if err != nil || len(out.Contents) == 0 {
return err
}
var objects []types.ObjectIdentifier
for _, obj := range out.Contents {
objects = append(objects, types.ObjectIdentifier{Key: obj.Key})
}
_, err = r.client.DeleteObjects(ctx, &s3.DeleteObjectsInput{
Bucket: aws.String(bucket),
Delete: &types.Delete{Objects: objects},
})
return err
}
func (r *S3Repository) GetStats(ctx context.Context, bucket string) (*BucketStats, error) {
out, err := r.client.ListObjectsV2(ctx, &s3.ListObjectsV2Input{Bucket: aws.String(bucket)})
if err != nil {
return nil, err
}
var totalSize int64
for _, obj := range out.Contents {
totalSize += aws.ToInt64(obj.Size)
}
return &BucketStats{
BucketName: bucket,
TotalFiles: int(len(out.Contents)),
TotalSizeBytes: totalSize,
TotalSizeFormatted: formatBytes(totalSize),
}, nil
}
func formatBytes(b int64) string {
const unit = 1024
if b < unit {
return fmt.Sprintf("%d B", b)
}
div, exp := int64(unit), 0
for n := b / unit; n >= unit; n /= unit {
div *= unit
exp++
}
return fmt.Sprintf("%.1f %cB", float64(b)/float64(div), "KMGTPE"[exp])
}Destaques técnicos na Infraestrutura
- Contexto (
context.Context): operações de rede respeitam cancelamento e timeout; se a requisição cair, eu evito trabalho inútil e consumo de recursos. - Paginação eficiente: essencial para buckets grandes; o cliente navega sem sobrecarregar a API.
- Presigned URLs: acesso temporário e seguro a bucket privado sem expor o bucket publicamente.
- Apresentação de dados: formatar tamanhos e metadados melhora muito a experiência de quem consome a API.
Camada de Serviço
Nesta camada fica a orquestração: validações, regras de negócio, timeouts e concorrência.
Um detalhe que eu gosto aqui: a interface Service expõe o “o que a aplicação faz”, enquanto a implementação concreta fica privada, forçando o uso de um construtor (factory). Isso ajuda a manter o design consistente e controlado.
package upload
import (
"context"
"fmt"
"io"
"log/slog"
"net/http"
"path/filepath"
"regexp"
"strings"
"time"
"github.com/google/uuid"
"golang.org/x/sync/errgroup"
)
type Service interface {
UploadFile(ctx context.Context, bucket string, file *File) (string, error)
UploadMultipleFiles(ctx context.Context, bucket string, files []*File) ([]string, error)
GetDownloadURL(ctx context.Context, bucket, key string) (string, error)
DownloadFile(ctx context.Context, bucket, key string) (io.ReadCloser, error)
ListFiles(ctx context.Context, bucket, ext, token string, limit int) (*PaginatedFiles, error)
DeleteFile(ctx context.Context, bucket string, key string) error
GetBucketStats(ctx context.Context, bucket string) (*BucketStats, error)
CreateBucket(ctx context.Context, bucket string) error
ListAllBuckets(ctx context.Context) ([]BucketSummary, error)
DeleteBucket(ctx context.Context, bucket string) error
EmptyBucket(ctx context.Context, bucket string) error
}
const (
uploadTimeout = 60 * time.Second
deleteTimeout = 5 * time.Second
maxBucketNameLength = 63
minBucketNameLength = 3
)
var (
// S3 bucket names seguem regras de DNS (min/max e charset). Regex cobre o padrão geral.
bucketDNSNameRegex = regexp.MustCompile(`^[a-z0-9][a-z0-9.-]{1,61}[a-z0-9]$`)
// Allowlist: valida tipo real do arquivo (MIME detectado) em vez de confiar na extensão.
allowedTypes = map[string]bool{
"image/jpeg": true,
"image/png": true,
"image/webp": true,
"application/pdf": true,
}
)
type uploadService struct {
repo Repository
}
func NewService(repo Repository) Service {
return &uploadService{repo: repo}
}
func (s *uploadService) UploadFile(ctx context.Context, bucket string, file *File) (string, error) {
ctx, cancel := context.WithTimeout(ctx, uploadTimeout)// evita requisição "pendurada" em chamadas ao S3
defer cancel()
if err := s.validateBucketName(bucket); err != nil {
return "", err
}
if err := s.validateFile(file); err != nil {
slog.Error("security validation failed", "error", err, "filename", file.Name)
return "", err
}
// UUID v7 mantém ordenação temporal e evita colisão/exposição de nomes originais.
id, err := uuid.NewV7()
if err != nil {
slog.Error("uuid generation failed", "error", err)
return "", fmt.Errorf("failed to generate unique id: %w", err)
}
file.Name = id.String() + filepath.Ext(file.Name)
url, err := s.repo.Upload(ctx, bucket, file)
if err != nil {
slog.Error("repository upload failed", "error", err, "bucket", bucket)
return "", err
}
file.URL = url
slog.Info("file uploaded successfully", "url", url)
return url, nil
}
func (s *uploadService) UploadMultipleFiles(ctx context.Context, bucket string, files []*File) ([]string, error) {
// errgroup cancela o contexto se qualquer goroutine falhar.
g, ctx := errgroup.WithContext(ctx)
results := make([]string, len(files))
for i, f := range files {
i, f := i, f // evita captura incorreta das variáveis do loop
g.Go(func() error {
url, err := s.UploadFile(ctx, bucket, f)
if err != nil {
return err
}
results[i] = url
return nil
})
}
if err := g.Wait(); err != nil {
return nil, err
}
return results, nil
}
func (s *uploadService) GetDownloadURL(ctx context.Context, bucket, key string) (string, error) {
if err := s.validateBucketName(bucket); err != nil {
return "", err
}
// Presign é a forma recomendada para acesso temporário a buckets privados.
return s.repo.GetPresignURL(ctx, bucket, key, 15*time.Minute)
}
func (s *uploadService) DownloadFile(ctx context.Context, bucket, key string) (io.ReadCloser, error) {
if err := s.validateBucketName(bucket); err != nil {
return nil, err
}
return s.repo.Download(ctx, bucket, key)
}
func (s *uploadService) ListFiles(ctx context.Context, bucket, ext, token string, limit int) (*PaginatedFiles, error) {
if err := s.validateBucketName(bucket); err != nil {
return nil, err
}
if limit <= 0 {
limit = 10
}
res, err := s.repo.List(ctx, bucket, "", token, int32(limit))
if err != nil {
return nil, err
}
if ext == "" {
return res, nil
}
var filtered []FileSummary
target := strings.ToLower(ext)
if !strings.HasPrefix(target, ".") {
target = "." + target
}
for _, f := range res.Files {
if strings.ToLower(f.Extension) == target {
filtered = append(filtered, f)
}
}
res.Files = filtered
return res, nil
}
func (s *uploadService) DeleteFile(ctx context.Context, bucket string, key string) error {
ctx, cancel := context.WithTimeout(ctx, deleteTimeout)
defer cancel()
if key == "" {
return fmt.Errorf("file key is required")
}
if err := s.validateBucketName(bucket); err != nil {
return err
}
return s.repo.Delete(ctx, bucket, key)
}
func (s *uploadService) GetBucketStats(ctx context.Context, bucket string) (*BucketStats, error) {
if err := s.validateBucketName(bucket); err != nil {
return nil, err
}
return s.repo.GetStats(ctx, bucket)
}
func (s *uploadService) CreateBucket(ctx context.Context, bucket string) error {
if err := s.validateBucketName(bucket); err != nil {
return err
}
exists, err := s.repo.CheckBucketExists(ctx, bucket)
if err != nil {
return err
}
if exists {
return ErrBucketAlreadyExists
}
return s.repo.CreateBucket(ctx, bucket)
}
func (s *uploadService) DeleteBucket(ctx context.Context, bucket string) error {
if err := s.validateBucketName(bucket); err != nil {
return err
}
return s.repo.DeleteBucket(ctx, bucket)
}
func (s *uploadService) EmptyBucket(ctx context.Context, bucket string) error {
if err := s.validateBucketName(bucket); err != nil {
return err
}
return s.repo.DeleteAll(ctx, bucket)
}
func (s *uploadService) ListAllBuckets(ctx context.Context) ([]BucketSummary, error) {
return s.repo.ListBuckets(ctx)
}
func (s *uploadService) validateBucketName(bucket string) error {
bucket = strings.TrimSpace(strings.ToLower(bucket))
if bucket == "" {
return ErrBucketNameRequired
}
if len(bucket) < minBucketNameLength || len(bucket) > maxBucketNameLength {
return fmt.Errorf("bucket name length must be between %d and %d", minBucketNameLength, maxBucketNameLength)
}
if !bucketDNSNameRegex.MatchString(bucket) {
return fmt.Errorf("invalid bucket name pattern")
}
if strings.Contains(bucket, "..") {
return fmt.Errorf("bucket name cannot contain consecutive dots")
}
return nil
}
func (s *uploadService) validateFile(f *File) error {
seeker, ok := f.Content.(io.Seeker)
if !ok {
return fmt.Errorf("file content must support seeking")
}
buffer := make([]byte, 512)
n, err := f.Content.Read(buffer)
if err != nil && err != io.EOF {
return fmt.Errorf("failed to read file header: %w", err)
}
// Reposiciona o stream para o início antes do upload.
if _, err := seeker.Seek(0, io.SeekStart); err != nil {
return fmt.Errorf("failed to reset file pointer: %w", err)
}
detectedType := http.DetectContentType(buffer[:n])
if !allowedTypes[detectedType] {
slog.Warn("rejected file type", "type", detectedType)
return ErrInvalidFileType
}
return nil
}Destaques técnicos no Serviço
Concorrência com errgroup
No upload múltiplo, eu não subo arquivo por arquivo. Eu disparo uploads em paralelo e deixo o errgroup gerenciar cancelamento: se um upload falhar, os demais são sinalizados para parar. Na prática, o tempo total tende a ser próximo do upload mais lento, e não a soma de todos.
Segurança: validação de tipo de arquivo
A validação lê um trecho do conteúdo para identificar o tipo real do arquivo, reduzindo risco de arquivos maliciosos com extensão “fingida”.
Resiliência: timeouts por operação
Operações como upload e delete têm características diferentes; por isso, faz sentido ter tempos limites distintos para manter a API responsiva e evitar recursos travados.
Encapsulamento e injeção de dependência
O Service depende de um Repository. Isso torna o código altamente testável: em testes, eu simulo o repositório com mocks sem precisar de AWS.
Camada de Handler
O Handler traduz HTTP para o mundo da aplicação: extrai parâmetros, valida o mínimo, chama o Service e retorna JSON (ou streaming no caso de download).
Eu utilizei o Gin pela combinação de performance, simplicidade e ecossistema de middlewares.
package upload
import (
"errors"
"io"
"net/http"
"strconv"
"github.com/gin-gonic/gin"
)
type Handler struct {
service Service
}
func NewHandler(s Service) *Handler {
return &Handler{service: s}
}
func (h *Handler) UploadFile(c *gin.Context) {
bucket := c.PostForm("bucket")
fileHeader, err := c.FormFile("file")
if err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": "file field is required"})
return
}
openedFile, err := fileHeader.Open()
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": "failed to open file"})
return
}
defer openedFile.Close()// garante que o stream do multipart seja fechado
file := &File{
Name: fileHeader.Filename,
Content: openedFile,// stream: evita carregar o arquivo inteiro em memória
Size: fileHeader.Size,
ContentType: fileHeader.Header.Get("Content-Type"),
}
url, err := h.service.UploadFile(c.Request.Context(), bucket, file)
if err != nil {
h.handleError(c, err)
return
}
c.JSON(http.StatusCreated, gin.H{"url": url})
}
func (h *Handler) UploadMultiple(c *gin.Context) {
bucket := c.PostForm("bucket")
form, err := c.MultipartForm()
if err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": "invalid multipart form"})
return
}
filesHeaders := form.File["files"]
if len(filesHeaders) == 0 {
c.JSON(http.StatusBadRequest, gin.H{"error": "no files provided"})
return
}
var filesToUpload []*File
for _, header := range filesHeaders {
openedFile, err := header.Open()
if err != nil {
continue
}
filesToUpload = append(filesToUpload, &File{
Name: header.Filename,
Content: openedFile,
Size: header.Size,
ContentType: header.Header.Get("Content-Type"),
})
}
// Fecha todos os streams abertos (mesmo em caso de erro no Service).
defer func() {
for _, f := range filesToUpload {
f.Content.Close()
}
}()
urls, err := h.service.UploadMultipleFiles(c.Request.Context(), bucket, filesToUpload)
if err != nil {
h.handleError(c, err)
return
}
c.JSON(http.StatusCreated, gin.H{"urls": urls})
}
func (h *Handler) GetPresignedURL(c *gin.Context) {
bucket := c.Query("bucket")
key := c.Query("key")
url, err := h.service.GetDownloadURL(c.Request.Context(), bucket, key)
if err != nil {
h.handleError(c, err)
return
}
c.JSON(http.StatusOK, gin.H{"presigned_url": url})
}
func (h *Handler) DownloadFile(c *gin.Context) {
bucket := c.Query("bucket")
key := c.Query("key")
stream, err := h.service.DownloadFile(c.Request.Context(), bucket, key)
if err != nil {
h.handleError(c, err)
return
}
defer stream.Close()
// Streaming: os bytes fluem do S3 para o cliente sem serem carregados em RAM pela API.
c.Header("Content-Disposition", "attachment; filename="+key)
c.Header("Content-Type", "application/octet-stream")
_, _ = io.Copy(c.Writer, stream)
}
func (h *Handler) ListFiles(c *gin.Context) {
limit, _ := strconv.Atoi(c.DefaultQuery("limit", "10"))
result, err := h.service.ListFiles(
c.Request.Context(),
c.Query("bucket"),
c.Query("extension"),
c.Query("token"),
limit,
)
if err != nil {
h.handleError(c, err)
return
}
c.JSON(http.StatusOK, result)
}
func (h *Handler) DeleteFile(c *gin.Context) {
err := h.service.DeleteFile(c.Request.Context(), c.Query("bucket"), c.Query("key"))
if err != nil {
h.handleError(c, err)
return
}
c.Status(http.StatusNoContent)
}
func (h *Handler) GetBucketStats(c *gin.Context) {
bucket := c.Query("bucket")
if bucket == "" {
c.JSON(http.StatusBadRequest, gin.H{"error": "bucket parameter is required"})
return
}
stats, err := h.service.GetBucketStats(c.Request.Context(), bucket)
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
c.JSON(http.StatusOK, stats)
}
func (h *Handler) CreateBucket(c *gin.Context) {
var body struct {
Name string `json:"bucket_name" binding:"required"`
}
if err := c.ShouldBindJSON(&body); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": "valid bucket_name is required"})
return
}
if err := h.service.CreateBucket(c.Request.Context(), body.Name); err != nil {
h.handleError(c, err)
return
}
c.Status(http.StatusCreated)
}
func (h *Handler) ListBuckets(c *gin.Context) {
buckets, err := h.service.ListAllBuckets(c.Request.Context())
if err != nil {
h.handleError(c, err)
return
}
c.JSON(http.StatusOK, buckets)
}
func (h *Handler) DeleteBucket(c *gin.Context) {
if err := h.service.DeleteBucket(c.Request.Context(), c.Query("name")); err != nil {
h.handleError(c, err)
return
}
c.Status(http.StatusNoContent)
}
func (h *Handler) EmptyBucket(c *gin.Context) {
bucket := c.Query("bucket")
if bucket == "" {
c.JSON(http.StatusBadRequest, gin.H{"error": "bucket parameter is required"})
return
}
err := h.service.EmptyBucket(c.Request.Context(), bucket)
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
c.Status(http.StatusNoContent)
}
func (h *Handler) handleError(c *gin.Context, err error) {
// Mapeia erros semânticos (domínio) para status HTTP.
switch {
case errors.Is(err, ErrInvalidFileType),
errors.Is(err, ErrBucketNameRequired):
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
case errors.Is(err, ErrBucketAlreadyExists):
c.JSON(http.StatusConflict, gin.H{"error": err.Error()})
case errors.Is(err, ErrFileNotFound):
c.JSON(http.StatusNotFound, gin.H{"error": err.Error()})
case errors.Is(err, ErrOperationTimeout):
c.JSON(http.StatusGatewayTimeout, gin.H{"error": "request timed out"})
default:
c.JSON(http.StatusInternalServerError, gin.H{"error": "an unexpected error occurred"})
}
}Decisões técnicas no handler
- Multipart/form-data sem “estourar RAM”: eu abro o arquivo como stream, evitando carregar tudo em memória.
- Streaming de download: crio um “cano” entre o S3 e o cliente. Isso permite suportar arquivos maiores com hardware modesto.
- Tratamento centralizado de erros: em vez de espalhar
if err != nilpor todas as rotas, o Handler mapeia erros semânticos do domínio para códigos HTTP consistentes (400, 404, 409, 504 etc.).
O ponto de entrada (main)
O main carrega configurações, instancia dependências e sobe o servidor. Aqui entra um dos conceitos mais úteis para manter projetos saudáveis: injeção de dependência.
Em termos práticos: o main cria o cliente AWS → passa para o repositório → passa para o service → passa para o handler. Isso deixa o sistema modular e fácil de testar.
package main
import (
"context"
"log/slog"
"os"
"time"
// Internal packages
appConfig "github.com/JoaoOliveira889/s3-api/internal/config"
"github.com/JoaoOliveira889/s3-api/internal/middleware"
"github.com/JoaoOliveira889/s3-api/internal/upload"
"github.com/gin-gonic/gin"
// External packages
configAWS "github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/service/s3"
"github.com/joho/godotenv"
)
func main() {
_ = godotenv.Load()// .env é útil em dev; em produção, prefira variáveis do ambiente/IAM Roles
cfg := appConfig.Load()
// Logs em JSON facilitam busca/indexação em ferramentas como CloudWatch/ELK/Loki.
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
slog.SetDefault(logger)
r := gin.New()
// Middlewares globais: aplicados a todas as rotas.
r.Use(middleware.RequestTimeoutMiddleware(cfg.UploadTimeout))
r.Use(middleware.LoggingMiddleware())
r.Use(gin.Recovery())// evita que um panic derrube o servidor inteiro
ctx := context.Background()
awsCfg, err := configAWS.LoadDefaultConfig(ctx, configAWS.WithRegion(cfg.AWSRegion))
if err != nil {
slog.Error("failed to load AWS SDK config", "error", err)
os.Exit(1)
}
// Injeção de dependência (bootstrap): client -> repo -> service -> handler.
s3Client := s3.NewFromConfig(awsCfg)
repo := upload.NewS3Repository(s3Client, cfg.AWSRegion)
service := upload.NewService(repo)
handler := upload.NewHandler(service)
api := r.Group("/api/v1")
{
api.GET("/health", func(c *gin.Context) {
c.JSON(200, gin.H{
"status": "healthy",
"env": cfg.Env,
"timestamp": time.Now().Format(time.RFC3339),
})
})
api.GET("/list", handler.ListFiles)
api.POST("/upload", handler.UploadFile)
api.POST("/upload-multiple", handler.UploadMultiple)
api.GET("/download", handler.DownloadFile)
api.GET("/presign", handler.GetPresignedURL)
api.DELETE("/delete", handler.DeleteFile)
buckets := api.Group("/buckets")
{
buckets.POST("/create", handler.CreateBucket)
buckets.DELETE("/delete", handler.DeleteBucket)
buckets.GET("/stats", handler.GetBucketStats)
buckets.GET("/list", handler.ListBuckets)
buckets.DELETE("/empty", handler.EmptyBucket)
}
}
slog.Info("server successfully started",
"port", cfg.Port,
"env", cfg.Env,
"region", cfg.AWSRegion,
)
if err := r.Run(":" + cfg.Port); err != nil {
slog.Error("server failed to shut down properly", "error", err)
os.Exit(1)
}
}Destaques técnicos na main
- Logging estruturado: logs em JSON são mais úteis para indexação e busca em ferramentas como CloudWatch, ELK ou Datadog.
- Middlewares em cadeia: aplico log e timeout globalmente, garantindo consistência em todas as rotas.
- Recovery: evita que um
panicderrube a API inteira. - Agrupamento e versionamento:
/api/v1facilita evolução sem quebrar clientes antigos.
Segurança e configuração: gerenciando credenciais
Para a API falar com a AWS, ela precisa de credenciais. Mas expor chaves no código é um risco sério. Por isso, em desenvolvimento local eu uso variáveis de ambiente (via .env) e, em produção, a evolução natural é usar IAM Roles.
Arquivo .env (desenvolvimento local)
Na raiz do projeto, criamos o arquivo .env. Ele servirá para armazenar configurações de servidor e as chaves secretas da AWS.
Atenção: Este arquivo deve estar obrigatoriamente no seu .gitignore. Nunca envie suas chaves para o GitHub ou qualquer outro sistema de controle de versão.
# Server Settings
PORT=8080
APP_ENV=development
# AWS Configuration
AWS_REGION=us-east-1
AWS_ACCESS_KEY_ID=SUA_ACCESS_KEY_AQUI
AWS_SECRET_ACCESS_KEY=SUA_SECRET_KEY_AQUI
# Application Settings
UPLOAD_TIMEOUT_SECONDS=60Obtendo Credenciais no Console AWS (IAM)
As chaves (Access Keys) são geradas no IAM. Para estudos você pode usar permissões amplas, mas o ideal é seguir o princípio do menor privilégio e restringir ao bucket e ações necessárias.
Passo a Passo:
- Acesse o IAM: No console da AWS, busque por “IAM”.
- Crie um Usuário: Vá em Users > Create user.
- Configuração: Defina um nome (ex: s3-api-manager). Não é necessário habilitar o acesso ao Console Visual (AWS Management Console) para este usuário, pois ele será usado apenas via código.
- Permissões (Princípio do Menor Privilégio): Escolha Attach policies directly.
- Nota: Para fins de estudo, você pode selecionar AmazonS3FullAccess. Em um cenário de produção real, o ideal é criar uma política personalizada que dê acesso apenas ao bucket específico que você irá usar.
- Gerar as Chaves: Após criar o usuário, clique no nome dele, vá na aba Security credentials e procure pela seção Access keys.
- Criação: Clique em Create access key, selecione a opção “Local code” e avance.
IMPORTANTE: Você verá a Access Key ID e a Secret Access Key. Copie e cole no seu .env agora, pois a Secret Key nunca mais será exibida.
Middlewares: observabilidade e resiliência
Middlewares são o lugar certo para comportamentos globais: logs, timeouts, correlação e proteção. Em vez de replicar isso por endpoint, eu centralizo.
Logging estruturado
O log é escrito após a requisição terminar. Isso permite registrar status code e latência com precisão, facilitando análise de performance e erros.
package middleware
import (
"log/slog"
"time"
"github.com/gin-gonic/gin"
)
func LoggingMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
start := time.Now()
path := c.Request.URL.Path
raw := c.Request.URL.RawQuery
c.Next()// executa o handler antes de logar, permitindo capturar status e latência reais
if raw != "" {
path = path + "?" + raw
}
slog.Info("incoming request",
"method", c.Request.Method,
"path", path,
"status", c.Writer.Status(),
"latency", time.Since(start).String(),
"ip", c.ClientIP(),
"user_agent", c.Request.UserAgent(),
)
}
}Controle de timeout
Em sistemas que dependem de serviços externos, é perigoso deixar conexões abertas indefinidamente. O middleware de timeout cancela a requisição quando ela excede um limite, liberando recursos.
package middleware
import (
"context"
"net/http"
"time"
"github.com/gin-gonic/gin"
)
func RequestTimeoutMiddleware(timeout time.Duration) gin.HandlerFunc {
return func(c *gin.Context) {
// Propaga um contexto com deadline para toda a cadeia (handlers + chamadas ao S3).
ctx, cancel := context.WithTimeout(c.Request.Context(), timeout)
defer cancel()
c.Request = c.Request.WithContext(ctx)
finished := make(chan struct{}, 1)
go func() {
c.Next()
finished <- struct{}{}
}()
select {
case <-finished:
return
case <-ctx.Done():
// Se estourar o deadline, aborta a request e devolve 504.
if ctx.Err() == context.DeadlineExceeded {
c.AbortWithStatusJSON(http.StatusGatewayTimeout, gin.H{
"error": "request timed out",
})
}
}
}
}Destaques técnicos Middlewares
c.Next()no momento certo: garante que o log capture status e latência reais.selecte canais: padrão claro para observar “terminou vs expirou”, mantendo o controle do ciclo de vida da requisição.- Logs estruturados: tornam mais fácil construir dashboards e alarmes.
Testes Unitários
Um dos maiores benefícios dessa arquitetura é a capacidade de testar a lógica de negócio isoladamente, sem AWS e sem internet.
Eu uso mocks para simular o repositório e foco em validar: regras de bucket, validações de tipo de arquivo, geração de identificadores e tratamento de erros.
package upload
import (
"context"
"io"
"time"
"github.com/stretchr/testify/mock"
)
type RepositoryMock struct {
mock.Mock
}
func (m *RepositoryMock) Delete(ctx context.Context, bucket string, key string) error {
panic("unimplemented")
}
func (m *RepositoryMock) DeleteAll(ctx context.Context, bucket string) error {
panic("unimplemented")
}
func (m *RepositoryMock) DeleteBucket(ctx context.Context, bucket string) error {
panic("unimplemented")
}
func (m *RepositoryMock) GetStats(ctx context.Context, bucket string) (*BucketStats, error) {
panic("unimplemented")
}
func (m *RepositoryMock) ListBuckets(ctx context.Context) ([]BucketSummary, error) {
panic("unimplemented")
}
func (m *RepositoryMock) Upload(ctx context.Context, bucket string, file *File) (string, error) {
args := m.Called(ctx, bucket, file)
return args.String(0), args.Error(1)
}
func (m *RepositoryMock) Download(ctx context.Context, bucket, key string) (io.ReadCloser, error) {
args := m.Called(ctx, bucket, key)
if args.Get(0) == nil {
return nil, args.Error(1)
}
return args.Get(0).(io.ReadCloser), args.Error(1)
}
func (m *RepositoryMock) GetPresignURL(ctx context.Context, bucket, key string, expiration time.Duration) (string, error) {
args := m.Called(ctx, bucket, key, expiration)
return args.String(0), args.Error(1)
}
func (m *RepositoryMock) List(ctx context.Context, bucket, prefix, token string, limit int32) (*PaginatedFiles, error) {
args := m.Called(ctx, bucket, prefix, token, limit)
return args.Get(0).(*PaginatedFiles), args.Error(1)
}
func (m *RepositoryMock) CheckBucketExists(ctx context.Context, bucket string) (bool, error) {
args := m.Called(ctx, bucket)
return args.Bool(0), args.Error(1)
}
func (m *RepositoryMock) CreateBucket(ctx context.Context, bucket string) error {
args := m.Called(ctx, bucket)
return args.Error(0)
}Implementando os Testes do Serviço
No arquivo service_test.go, focamos em testar as regras de negócio: validação de nomes de bucket, geração de UUID e tratamento de erros.
package upload
import (
"context"
"strings"
"testing"
"time"
"github.com/stretchr/testify/assert"
"github.com/stretchr/testify/mock"
)
type readSeekCloser struct {
*strings.Reader
}
func (rsc readSeekCloser) Close() error { return nil }
func TestUploadFile_InvalidBucket(t *testing.T) {
mockRepo := new(RepositoryMock)
service := NewService(mockRepo)
result, err := service.UploadFile(context.Background(), "", &File{})
assert.Error(t, err)
assert.Empty(t, result)
assert.ErrorIs(t, err, ErrBucketNameRequired)
}
func TestUploadFile_Success(t *testing.T) {
mockRepo := new(RepositoryMock)
service := NewService(mockRepo)
ctx := context.Background()
content := strings.NewReader("\x89PNG\r\n\x1a\n" + strings.Repeat("0", 512))
file := &File{
Name: "test-image.png",
Content: readSeekCloser{content},
}
bucket := "my-test-bucket"
expectedURL := "https://s3.amazonaws.com/my-test-bucket/unique-id.png"
mockRepo.On("Upload", mock.Anything, bucket, mock.AnythingOfType("*upload.File")).Return(expectedURL, nil)
resultURL, err := service.UploadFile(ctx, bucket, file)
assert.NoError(t, err)
assert.NotEmpty(t, resultURL)
assert.Equal(t, expectedURL, resultURL)
mockRepo.AssertExpectations(t)
}
func TestGetDownloadURL_Success(t *testing.T) {
mockRepo := new(RepositoryMock)
service := NewService(mockRepo)
bucket := "my-bucket"
key := "image.png"
expectedPresignedURL := "https://s3.amazonaws.com/my-bucket/image.png?signed=true"
mockRepo.On("GetPresignURL", mock.Anything, bucket, key, 15*time.Minute).
Return(expectedPresignedURL, nil)
url, err := service.GetDownloadURL(context.Background(), bucket, key)
assert.NoError(t, err)
assert.Equal(t, expectedPresignedURL, url)
mockRepo.AssertExpectations(t)
}
Destaques técnicos nos testes
- Testar regra, não integração: o Service precisa ser previsível; integrações ficam para testes específicos.
- Validação de segurança refletida nos testes: se a API valida MIME, os testes precisam respeitar isso para serem realistas.
errors.Ise erros semânticos: isso fortalece consistência e facilita assertivas.
Automação com GitHub Actions
A cada push/PR, o CI instala dependências e roda testes. Isso mantém a branch principal estável e reduz o risco de regressão.
Configurando o Workflow (go.yml)
O arquivo de configuração deve ser criado em .github/workflows/go.yml. Ele define os passos necessários para validar a saúde do projeto.
# .github/workflows/go.yml
name: Go CI
on:
push:
branches: [ main, develop ]
pull_request:
branches: [ main ]
jobs:
test:
name: Run Tests
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Set up Go
uses: actions/setup-go@v5
with:
go-version: '1.25.5'
cache: true
- name: Install dependencies
run: go mod download
- name: Verify dependencies
run: go mod verify
- name: Run tests
run: go test -v -race ./...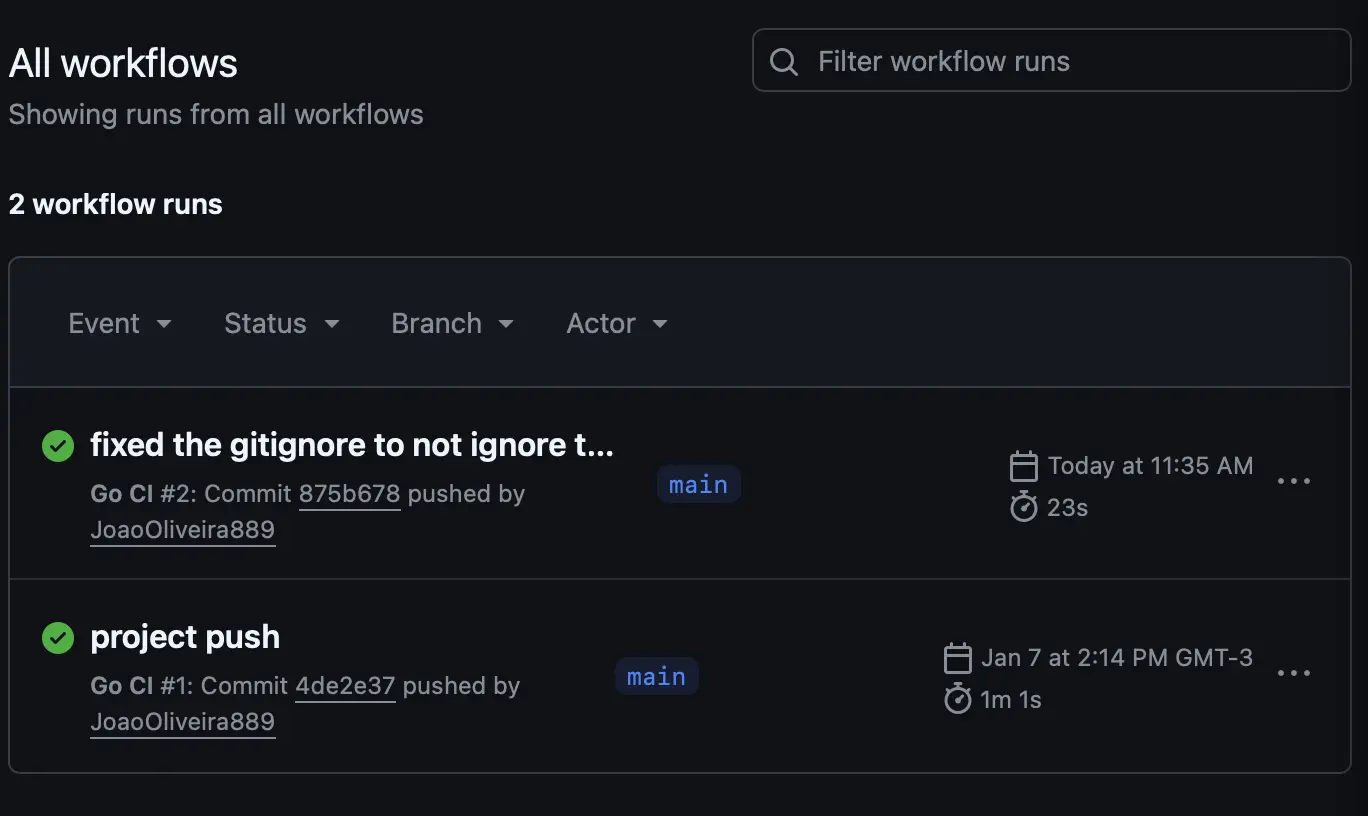
Destaques técnicos na Automação
- Race detector (
-race): importante porque há concorrência (uploads paralelos). - Cache de dependências: acelera builds e economiza tempo de execução.
- Pipeline seguro: como o Service é testado com mocks, o CI não precisa de credenciais AWS.
Configurações Centralizadas
Em projetos pequenos, é comum espalhar os.Getenv. Em projetos que crescem, isso vira dívida técnica: dependências ficam implícitas e difíceis de rastrear.
Centralizar config cria uma “fonte única da verdade”: validação e tipagem no início da execução e consumo simples no restante do código.
package config
import (
"os"
"strconv"
"time"
)
type Config struct {
Port string
AWSRegion string
UploadTimeout time.Duration
Env string
}
func Load() *Config {
return &Config{
Port: getEnv("PORT", "8080"),
AWSRegion: getEnv("AWS_REGION", "us-east-1"),
// Converte o valor uma única vez para time.Duration,
// evitando cálculos repetidos no restante da aplicação.
UploadTimeout: time.Duration(getEnvAsInt("UPLOAD_TIMEOUT_SECONDS", 30)) * time.Second,
Env: getEnv("APP_ENV", "development"),
}
}
func getEnv(key, defaultValue string) string {
if value, exists := os.LookupEnv(key); exists {
return value
}
return defaultValue
}
func getEnvAsInt(key string, defaultValue int) int {
valueStr := getEnv(key, "")
if value, err := strconv.Atoi(valueStr); err == nil {
return value
}
return defaultValue
}Erros Semânticos
O Service não deve retornar códigos HTTP. Ele deve retornar erros que façam sentido no domínio, e o Handler decide o status adequado. Isso mantém o domínio reutilizável (HTTP hoje, gRPC amanhã, CLI depois).
package upload
import "errors"
var (
ErrBucketNameRequired = errors.New("bucket name is required")
ErrFileNotFound = errors.New("file not found in storage")
ErrInvalidFileType = errors.New("file type not allowed or malicious content detected")
ErrBucketAlreadyExists = errors.New("bucket already exists")
ErrOperationTimeout = errors.New("the operation timed out")
)Destaques técnicos nos Erros
- Domínio agnóstico: erros continuam fazendo sentido fora do HTTP.
- Comparação robusta com
errors.Is: mais seguro do que comparar strings. - Consistência: mensagens estáveis e previsíveis para quem consome a API.
Containerização com Docker
Containerizar garante que a API rode da mesma forma em qualquer ambiente. Aqui eu uso multi-stage build: compilo em uma imagem com toolchain e rodo em uma imagem final menor e mais segura.
Dockerfile otimizado
services:
s3-api:
build: .
ports:
- "8080:8080"
env_file:
- .env
restart: alwaysOrquestração com Docker Compose
O docker-compose.yml simplifica a inicialização da aplicação, gerenciando as portas e carregando automaticamente o nosso arquivo de segredos (.env).
# Stage 1: Build the Go binary
FROM golang:1.25.5-alpine AS builder
WORKDIR /app
# Copy dependency files
COPY go.mod go.sum ./
RUN go mod download
# Copy the source code
COPY . .
# Build the application with optimizations
RUN CGO_ENABLED=0 GOOS=linux go build -ldflags="-w -s" -o main ./cmd/api/main.go
# Stage 2: Create the final lightweight image
FROM alpine:latest
RUN apk --no-cache add ca-certificates
WORKDIR /root/
# Copy the binary from the builder stage
COPY --from=builder /app/main .
# Copy the .env file (optional, better to use environment variables in prod)
COPY --from=builder /app/.env .
EXPOSE 8080
CMD ["./main"]Destaques técnicos Docker
- Certificados SSL: imagens mínimas nem sempre vêm com CA certs; sem isso, chamadas HTTPS podem falhar.
- Binário enxuto: flags de build reduzem tamanho e aceleram deploy.
- Cache inteligente: copiar
go.mod/go.sumantes do código ajuda o Docker a reaproveitar layers.
Comandos Úteis
Testes
go test ./...Executar o projeto
go run cmd/api/main.goGestão do Container
# Construir a imagem e subir o container em background
docker-compose up --build -d
# Visualizar logs da aplicação em tempo real
docker logs -f go-s3-api
# Derrubar o container
docker-compose downConclusão
Construir esta API de gerenciamento para o Amazon S3 foi uma forma prática de unir uma necessidade real (automatizar meu workflow do blog) com aprendizado sólido (Go, AWS, segurança, observabilidade e arquitetura).
Links do projeto
Repositório Principal no GitHub: Este é o repositório “vivo”, que pode evoluir e ficar diferente do que está descrito neste artigo.
Código Versão do Artigo: Para ver o projeto exatamente como foi construído e explicado aqui, com estado estático.
Referências
- Go Standard Project Layout: https://github.com/golang-standards/project-layout
- Clean Architecture (The Clean Code Blog): https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
- WS SDK for Go v2 - S3 Developer Guide: https://aws.github.io/aws-sdk-go-v2/docs/getting-started/
- Go Concurrency Patterns (Context Package): https://go.dev/blog/context
- Gin Web Framework: https://gin-gonic.com/docs/
- Testify - Testing Toolkit: https://github.com/stretchr/testify
- Google UUID Package (v7 support): https://github.com/google/uuid
- Errgroup Package (Concorrência): https://pkg.go.dev/golang.org/x/sync/errgroup
- Dockerizing a Go App: https://docs.docker.com/language/golang/build-images/
- GitHub Actions for Go: https://github.com/actions/setup-go